今回は第841回 で紹介したAlpacaを、AMD Radeonで動作させる方法を具体的に紹介します。また、今おすすめのモデルも紹介します。
この2か月間のAlpacaの進歩
Alpaca は、つい2か月ほど前の第841回 で紹介したばかりですが、あらためて紹介する価値があると考えたので今回の記事の執筆を決意しました。
第841回で紹介した際のAlpacaのバージョンは2.9.0で、本文中にもあるように不具合でAMD Radeonを認識しませんでした。しかし、次のバージョン(3.0.0)で修正されています。
そればかりか、Xセッションで候補ウィンドウを表示した状態でのエンターキー入力が効かない問題が修正されています。
さらに、翻訳までされています。執筆時点でのバージョンは4.0.0で、モデルの管理(モデルマネージャー)のユーザーインターフェースが刷新されたことにより未訳の部分もありますが、日本語になったことによりとっつきやすくなりました。
ついでにおすすめのモデルもいくつか紹介しますが、gihyo.jpの機械学習・AI カテゴリーを見てもわかるとおり、来月になったらたぶんおすすめのモデルはまた別のものになっていることが予想されるくらいには日々いろいろなものがリリースされています。そのくらい進化が早いのが面白いところで、( 世間の相場から考えて)少しお高めのGPUが必要なものの、手元にあればいつでもその海に潜ることができます。
PCのスペック
今回使用したPCのスペックは次のとおりです。
メーカー
型番
備考
CPU
AMD
Ryzen 9 7950X
105W運用
CPUファン
ID-COOLING
IS-55-BLACK
マザーボード
ASRock
B650M Pro RS
メモリー
Team
CTCCD532G6000HC48DC01-A
DDR5 6000MHz 16GB*2
GPU
ASRock
RX7800XT CL 16GO
Radeon RX 7800XT
SSD
キオクシア
EXCERIA SSD-CK480S
電源
Silver Stone
SX-700G
2.5インチフロントベイ
Silver Stone
FS202
ケース
Silver Stone
SG11
筆者は2.5インチSSDを入れ替えることによって複数の検証環境を用意しています。さらにパッケージのビルド環境も兼ねているためこのようなCPUを搭載していますが、生成AIを動作させるだけであればこれほどのCPUパワーは不要です。
ポイントはやはりRX7800XT CL 16GO で、スロットを2.5個分使用することを許容できるのであれば、なかなかにいい選択肢と考えます。どうしても2スロットで抑えたい場合や、 7.5万円(筆者の購入価格)の捻出が難しい場合は、下位モデルであるRX7600XT CL 16GO でもいいでしょう。しかし1.5倍の価格差でストリームプロセッサが約2倍、メモリーの帯域が2倍であることを考えると、RX7800XT CL 16GOがおすすめではあります。
Alpacaのインストール
Alpacaのインストールは第841回に書いてあるとおりです。
$ flatpak install flathub com.jeffser.Alpaca この2行目がRadeonを使用する際のポイントです。
また使用しているユーザーがrenderグループに属していない場合は、次のコマンドを実行してください。
$ sudo usermod -a -G render $USER
このコマンドを実行した場合は、再起動が必要です。
動作確認
第841回では端末からの起動をおすすめしていましたが、現在のバージョンではあまりコンソールにメッセージを表示しなくなったので、意味がなくなりました。普通にアイコンから起動してください。
図1 のように、メニューが日本語化されてます。
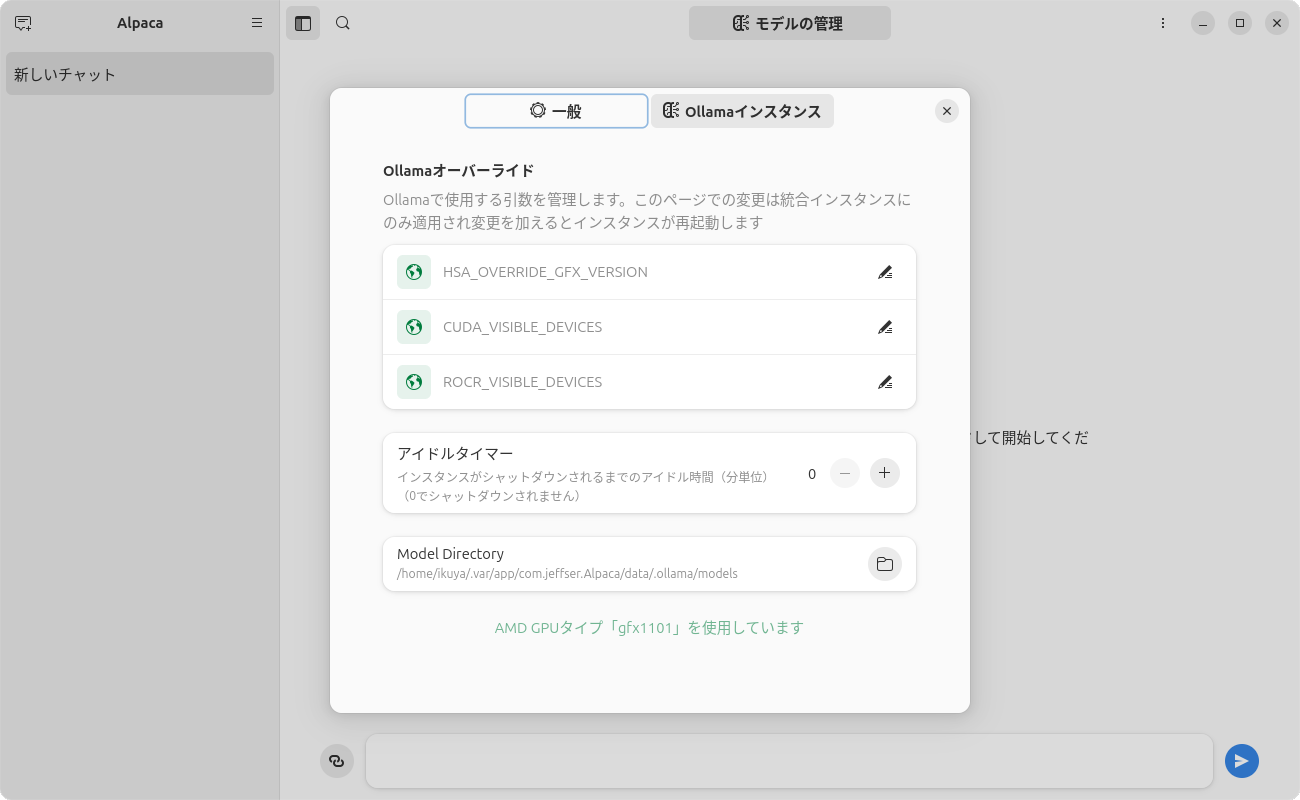
図1 日本語化されたメニュー「設定」 -「 Ollamaインスタンス」を見てみると、「 AMD GPUタイプ「gfx1101」を使用しています」と表示されます(図2 ) 。サポートされているGPUのリストはこちら です。
図2 Radeon RX 7800XTはgfx1101として認識されるこのリストを見てもわかるように、基本的にはRadeon RX 6400/6500 XT/6600 XTには対応していません。しかし「HSA_OVERRIDE_GFX_VERSION」に「10.3.0」と入力して登録し、Alpacaを再起動すると使用できるようになる、こともあります。筆者が試したところでは、うまくいってます。
おすすめのモデル
VRAMが16GBのGPUでは、14B前後のモデルであれば快適に動作するので、そちらを目安に探します。
DeepSeek-R1
DeepSeek-R1の紹介記事はこちら を参照してください。良くも悪くも話題になっていて、まず始めるのはこれからにしてみると面白いでしょう。
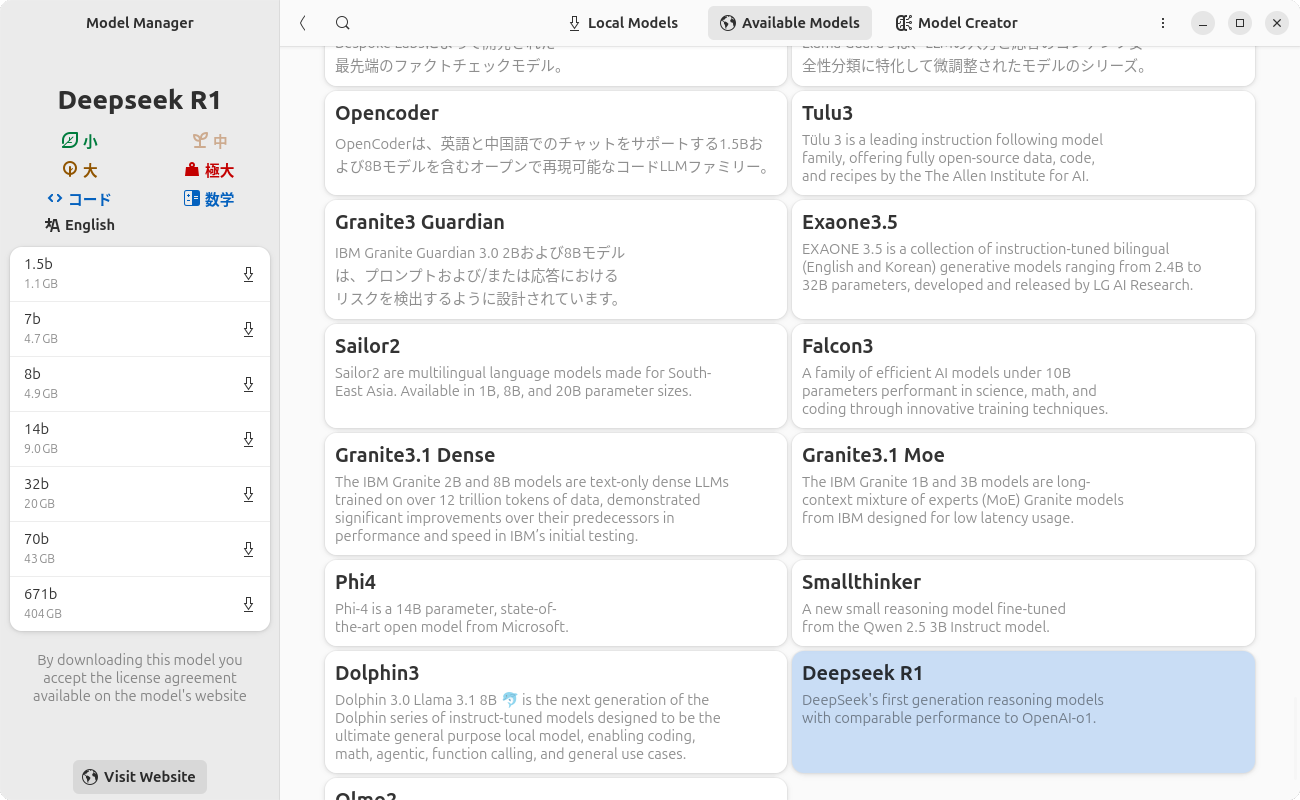
「モデルマネージャーを開く」またはハンバーガーメニューの「モデルの管理」をクリックし、「 Available Models」に「Deepseek R1」があるのでこれをクリックし(図3 ) 、左ペインに表示されるリストから「14b」をクリックします。ダウンロードが開始するので、しばらく待ちます(図4 ) 。
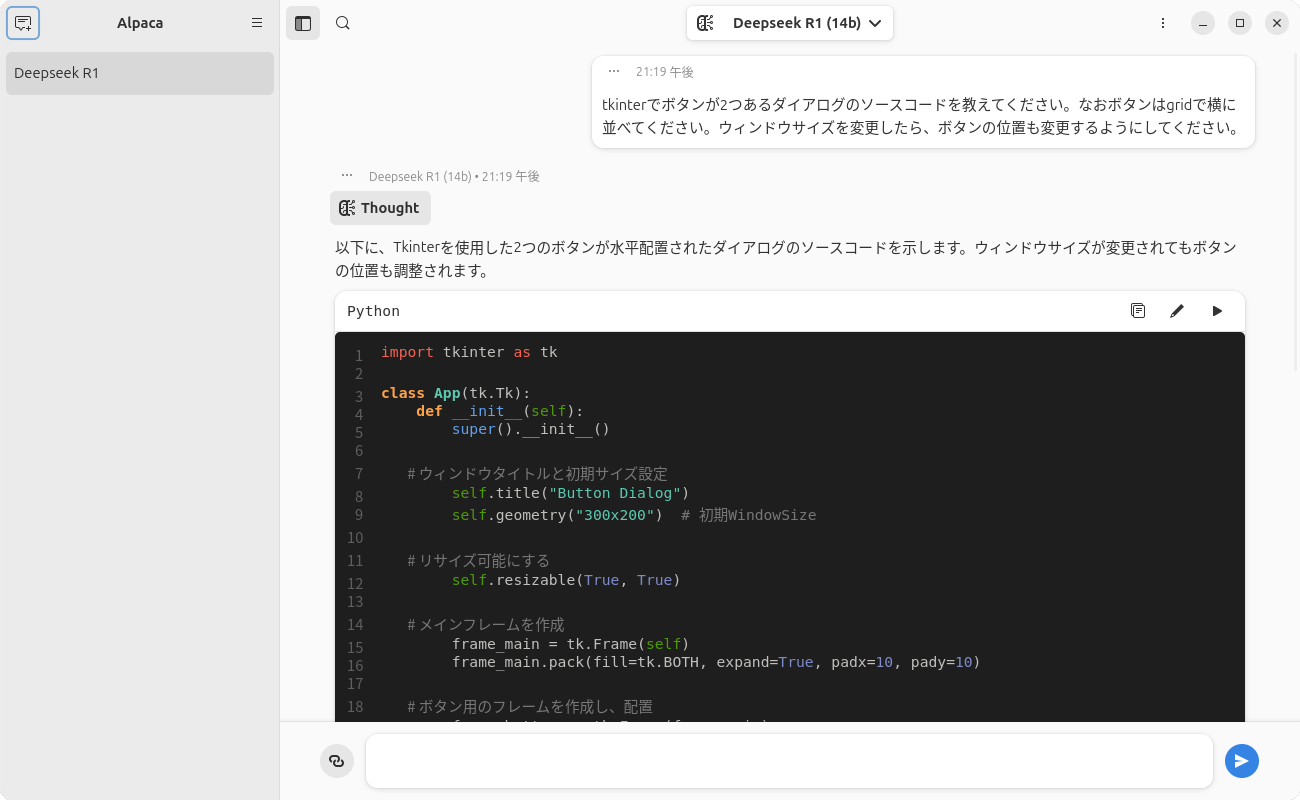
図3 Deepseek R1をクリックしたところ図4 Deepseek R1のモデルがダウンロードできたあとはメイン画面に戻って、上部で「Deepseek R1 (14b)」を選択して質問を開始します(図5 ) 。
図5 Deepseek R1で質問をしているところPhi-4
Phi-4の紹介記事はこちら を参照してください。実は個人的にはDeepSeek-R1よりもこちらのほうが気に入ってます。
インストールする方法はDeepSeek-R1とおおむね同じです。こちらは14Bのモデルしかないため、よりシンプルです。図6 が実際に使用しているところです。
図6 正直なところ、Phi-4の出力するコードが一番しっくりくるDeepSeek-R1-Distill-Qwen-14B/32B-Japanese
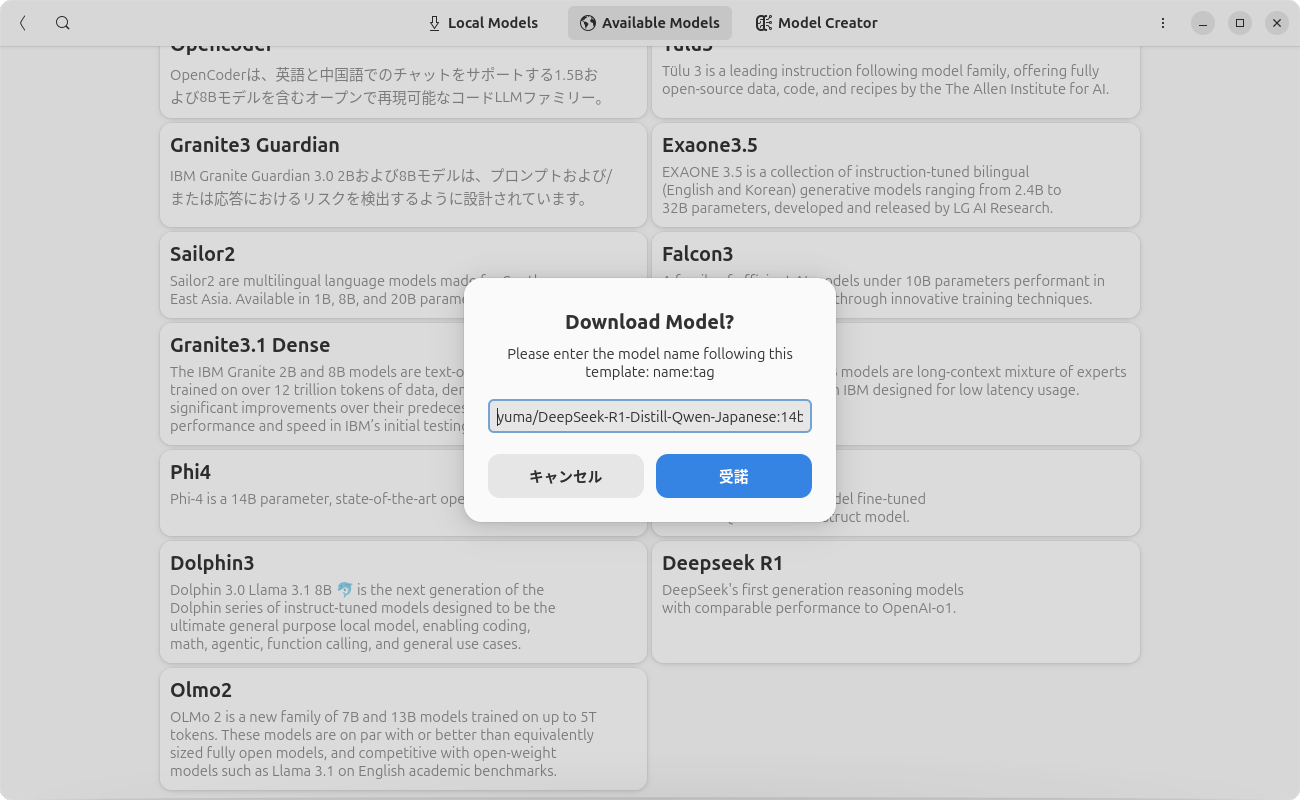
DeepSeek-R1-Distill-Qwen-14B/32B-Japaneseの紹介記事はこちら を参照してください。「 Available Models」にはありませんが、モデルとしては存在 します。このような場合のインストール方法は、右側にあるケバブメニューをクリックし、表示される「Download Model From Name」をクリックします。ここにモデル名(今回だと「yuma/DeepSeek-R1-Distill-Qwen-Japanese:14b」 )を入力し、「 受諾」をクリックします(図7 ) 。
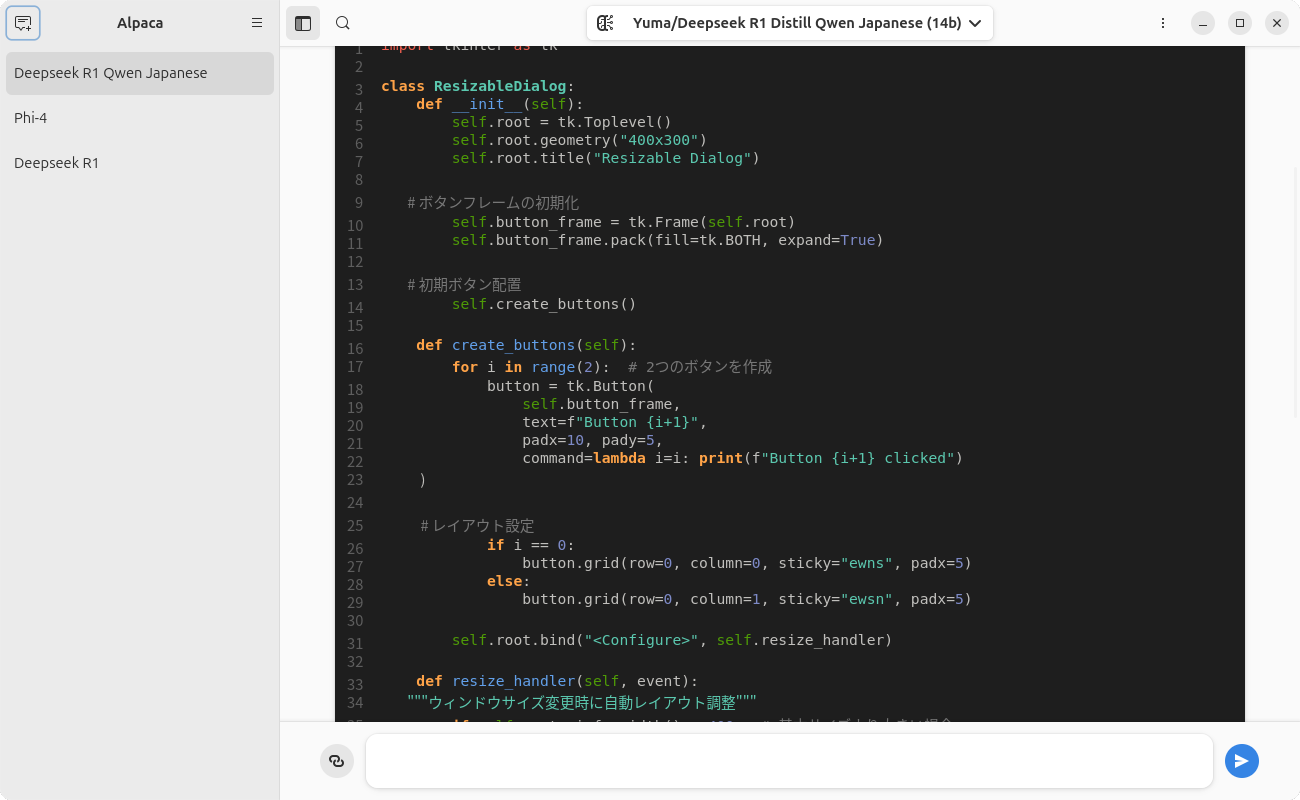
図7 リストにないモデルのダウンロード方法あとはほかのモデルと同様です。図8 が実際に使用しているところです。
図8 DeepSeek R1の蒸留モデルなので似たようなソースコードを出力するのかと予想していたら、全く違うもので驚いたGemma 2 JPN 2B
VRAMが16GBもある場合はモデルも選び放題ですが(もっと多いとさらに選び放題ですが) 、VRAMが4GBしかなく、小さいモデルで動かしたい場合もあります。そんな場合には「Gemma 2 JPN 2B」がいいでしょう(紹介記事 ) 。
インストール方法は「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」に準じ、「 Download Model From Name」には「schroneko/gemma-2-2b-jpn-it」と入力します。
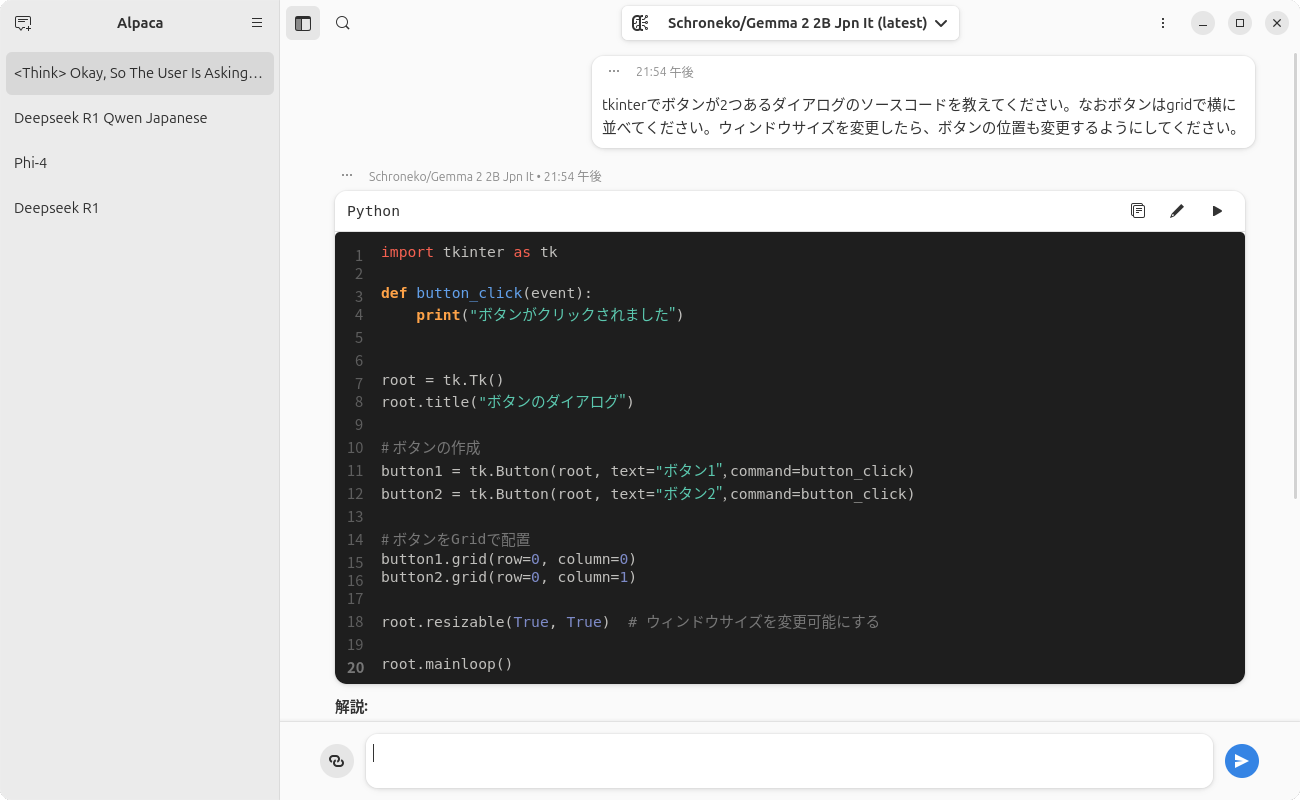
図9 が実際に使用しているところです。
図9 Pythonのソースコードとしてはかなりおかしなものが出力されている